Objective: Demo on Table Partitioning , re-partitioning.
What is Table-Partitioning?
Table-Partitioning is done to improve the query performance with the cube and has to done after the cube has been created and before data has been loaded into the cube. This type of partitioning is also called as “Range Partitioning”.
What is the use of Partitioning?
Using Partitioning it is possible to distribute the entire data set of a cube into several independent, small redundancy free-units and by performing this we can improve the reporting performance and delete the data from the cube.
What are the pre-requisites for Partitioning?
Partitioning can be implemented using time info-object only. The two info-objects that can be used for partitioning are calender month(0CALMONTH) and fiscal year/period(0FISCPER). Hence the cube must contain atleast one of the two info-objects.
What are the databases that support Partitioning?
Only some databases such as ORACLE, INFORMIX etc support this feature. If we use DB/400 as the database platform then the database version that we can use must be atleast V5R3M0 and the component DB2 multi-systems must be installed. In case if we use database that does not support this function, then this is not provided in BI system.
Let us consider an example to demonstrate partitioning using 0CALMONTH….
We will create a cube ‘ ZPARTI’ with 0CALMONTH , Customer and Purchasing Unit and the option for creating Partitions is shown below….

We will assume the value range from 01.2006 to 12.2007….
When we click on the Partitioning it will prompt for 0CALMONTH as shown below….

It calculates in the following way….
2 years * 12 months + 2 = 26 partitions are created ( 2 partitions that lie outside the range that is before 01.2006 and after 12.2007).Say for example we choose 10 partitions…
Now the system summarizes every 3 months into a partition ( that is one partition corresponds to excatly one quarter), therefore 2 years * 4 partitions/year + 2 marginal partitions = 10 partitions are created on the database.
Now enter the inputs as per the above calculation….

We can check the number of partitions created in the table RSDCUBE in SE16.Enter the cube name and select the fields PARTVL_FROM, PARTVL_TO, PARTMAXCNT to find the upper limit, lower limit and number of partitions created….

Output in RSDCUBE....

Now load the cube with some sample data which as shown below….

Partition on demad: Partition on demand means that we should not create partitions that are too small or too large. Say, for example if we choose a time period that is too small then the number of partitions will be more and if we choose a time period that ranges too far then the number of partitions will be too great. So it is recommended to create a partition for a year that is we can repartiton the cube after this time. This is where the concept of re-partitioning comes into existence….What is the use of re-partitioning?The concept of re-partitioning is useful if we have already loaded the data into the cube with follwing one of the follwing steps…a) If we did not create the partition when we have created it. b) We have loaded more data into the cube than what we have partitioned.
c) If we did not choose long enough time for partitioning
d) Some partitions may contain less data or no data due to data archiving over certain period.
Note: It always recommended taking data backup before doing re-partitioning.
Info cube partitions are either merged at the bottom or added at the top.
If we want to merge the partitions which are empty or no data has been loaded outside of the time period initially defined. In this case the runtime takes only a few minutes. If there is data in the partitions in which we want to merge or if data has been loaded beyond the time period than initially defined, then the system will save the data in a shadow table and then copies it to original table. Here the runtime depends on the amount of data the system has to copy.
We can also merge and add partitions for aggregates as well as cubes and we can reactivate all the aggregates after the cube has been changed.
We can start re-partitioning by right clicking on the cube and selection Repartitioning option as shown….

1. For appending partitions follow the below procedure....

As mentioned before it is recommended to take a backup before repartitioning as shown….

Enter the value range in the upper limit upto which you want to extend the partition and specify the partitions. In this case we are appending from 12.2007 to 06.2008 and increasing 2 partitions( 10+2).
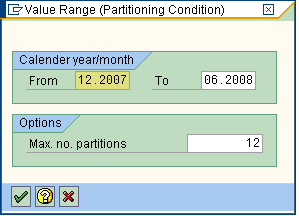
Now a request will be created to attach new partitions....

The job will scheduled in background to complete the request created....

In the monitor below it is clear that the patitions are appended....

In RSDCUBE we can check that partitions are created successfully....

2. Merging of created patitions
Select the option of merging partitions as shown below....

"
In this case we are merging from 01.2006 to 12.2007 we in after merging we must get 5 patitions i.e 01.2006 to 12.2007,01.2008 to 03.2008, 04.2008 to 06.2008 and two marginal partitions.

A request will be created to merge the patitions.

A background job is scheduled to the request for merging partitions....

The request is completed successfully by merging the partitions from 01.2006 to 12.2007

It RSDCUBE we check the that there are 5 partitions available after merging has been done as explained above....

3.Complete Partitioning:
This method completely converts the fact tables of the cube. Here new shadow tables are created by the system and copies all the data from the original tables into shadow tables. After completing the data copying, indexes are created and the original table replaces the shadow table. Finally after the partitioning request is completed, both the fact tables exist in the original state (shadow table) as well as in modified state with the new partitioning schema (original table). After repartitioning is completed, to free up the memory space we can delete the shadow tables manually. The namespace of the shadow tables is /BIC/4F and /BIC/4E.
Select the complete partitioning option as shown below....
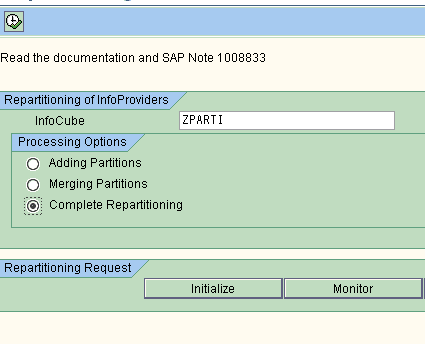
we have to take the data back before proceeding further.( recommended )

Since we are perfforming complete partitioning it prompts on what criteria we are doing patitioning and here we will take 0CALMONTH.

Now we are doing complete partitioning from 01.2006 to 06.2008 and let make it into 7 partitions....

If there are any aggregates available for the cube we have click on YES so that they will be rebuilt after partitioning....

As usually an new patitioning request will be created....

A background job is scheduled to complet the request.

In the monitor it is clear that complete patitioning is done from 01.2006 to 06.2008

In RSDCUBE we can check that 7 partitions are created as per the specification....

