Cross reference
Cross referencing at its simplest is the process of taking a source data value, comparing that source value to a list of values on an external data source (normally a relational data store), retrieving the corresponding target value, and applying that target value to the outgoing data stream to allow proper identification in the recipient system. A common example is a material master that may be identified as ‘Mat A' in a sending system but as ‘Material 101' in a recipient system. From the sending systems perspective, it has no knowledge of the target system identification and vice versa. As such, each system identifies the material only through its identification known to itself, requiring that an intermediary process in the data exchange cross reference the source value to the target value prior to receipt at the target system. This intermediary process is often filled by an EAI (Enterprise Application Integration) tool that performs the cross reference as well as the other necessary transformations. The basic example is shown in the following diagram (assuming a data flow from left to right):
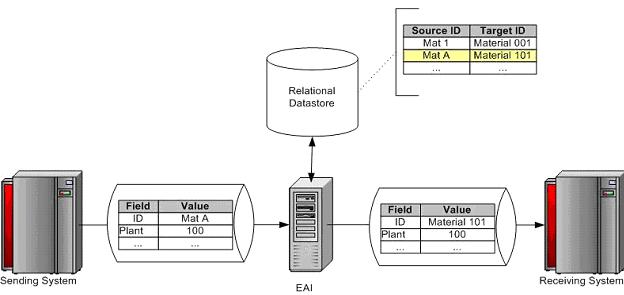
The reality is much more complex and critical. The majority of interfaces will require some form of cross reference (referred to forward as ‘Xref' for simplicity). Xref, from a performance perspective, are one of the largest time ‘consumers' within the execution of an interface. Data stores need to be robust / available and kept up to date as soon as the related source / target identification values are changed in their respective systems. Neglecting any of these areas will at the minimum result in execution degradation, and at the worst case execution failure. As such, the Xref approach must be given careful consideration prior to any interface design / development with a focus on the following areas:
- Maintains Performance: Maximizes performance from the establishment of the relational data store connection to the Xref request execution to the retrieval / formatting of that data.
- Robust: Guarantees transactional integrity, integrated error handling / restart / recovery.
- Promotes Re-use: Integrates easily to existing developments and designed generically enough to address a large scope of Xref needs dynamically with minimal, if any , modification.
- Simplifies Maintenance: Minimizes the number of ‘routines' to be maintained and promotes centralized / standard maintenance of those routines.
Access Methods
Once created, these tables need to be accessible from external systems (in this case EAI). The following alternatives exist:
External Source
JDBC / ODBC - Direct access to the tables via SQL or stored procedures
In this case data values are maintained in a separate external database (Relational) Generally Oracle, DB2 or SQL Server is taken as standard relational database. We need java class to achieve this.
Web Services - Custom access functions can be defined in Cross Ref external DB and exposed as web services to external systems.
SAP DB via ABAP Stack
JCo
In this case data value are maintained through SAP itself in the under lying DB. We need a RFC to interact between SAP & external system and also need java class to handle this.
Xref can be possible in other ways also like both the above ways are combined in one scenario itself i.e. for SAP system Xref are maintained in SAP where as for legacy system Xref are maintained in External DB.
All the other ways or possibilities are generally the combining effect of the basic two procedures mention above.
Direction: JDBC / ODBC access is the chosen / preferred method as it does not require explicit development on the Legacy side. Further it simplifies the communication via direct access maintainable from the EAI side. Currently there is no additional business requirement to warrant generating web services for Xref table access.
Maintenance
Xref processes are only as good as the data they retrieve, requiring this Xref data stay as up to date as possible. Initially this Xref data is created during the conversion process. From this point forward, the data must be updated / maintained as necessary for interface executions to follow.
Initially
As part of the data cleansing process within Legacy, incoming Legacy values are de-duplicated, normalized and summarized into distinct values within database tables. Upon loading into SAP, the corresponding SAP values are updated into those tables.
Ongoing - Automatically
Ideally, as much as is possible, Xref values are to be maintained automatically without user interaction. This would occur at the time of data creation in the source system and be interfaced to the Xref tables for update. This not only eliminates user effort but also the inherent data entry errors normally associated with manual entry. This can be accomplished in a couple of ways:
- At Xref Data Modification - At the time of creation of data (with Xref implications) in SAP, this would be sent via user exit from the SAP transaction to XI which in turn would update the Xref tables. This assumes SAP as the primary distributor of data with Xref implications.
- At Xref Data Transmission - Once data has been modified in the sending system it will ultimately be transferred to XI for downstream system distribution. At this time the message would be multi-cast within XI and the ‘copy' sent to a mapping that would perform the Xref table update. This assumes the Xref data (both source and target identifications) are present in the message and valid.
Ongoing - Manually
In the majority of instances, it will not be realistic that the sending system will have access to the target value (which is normally the reason for establishing an external Xref process through EAI). In these cases it will be necessary for end users to enter the values manually. This process should be easily accessible by end users, secure to ensure access to only those data areas allowed, and standard in regards to the process for updating any Xref table. The following alternatives are available:
- Legacy Tools - Within the Legacy toolset, there are inherent utilities / services for updating the underlying tables.
- Portal - A custom portal would be created to allow a centralized user access for table maintenance.
- Custom Java App - Tied into the portal or external, the java app would be leveraged against similar previously created tools (J.E.D.I.) for user access.
Related Content
Optimizing Lookup's in XI
Data Lookup Optimized
siva.maranani/blog/2005/08/23/lookup146s-in-xi-made-simpler
