Prior/Later Unicode Conversion Episodes [updated 12-Feb-2008]
- 0.001 - [Destroyed by space pirates]
- 0.002 - Community Day and Onward
- 0.003 - Revenge of The Space Monster
- 0.004 - Children of Murphy
- 0.005 - Journey to the Edge of Quality
- 0.006 - The Calm Before the Storm of Quality
- 0.007 - Passage to Production
- 0.008 - Unicode The Final Descent
- 1.000 - The Final Chapter
This past weekend (07-Dec through 09-Dec-2007) we converted 3 systems to Unicode - our North American R/3 development system, and the SCM development pair (SCM and Live Cache). There were a few surprises, and we're still working through a couple of them. Our mutual friend Mr. Murphy also stopped by uninvited.
Graphs
Tom Jung just Google Charting API Wrapper for ABAPabout the Google Chart API, but meanwhile I've been trying out a package with the unlikely name ofploticus. Below are CPU graphs from each conversion environment.
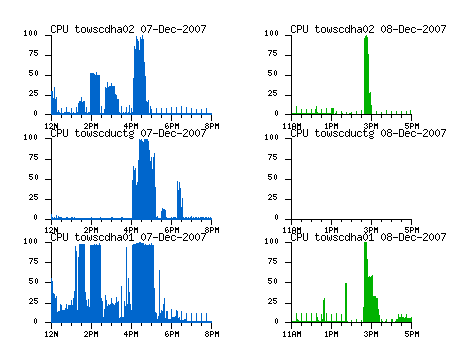
Throughput (times 2)
The above graphs show 2 sets of CPU spikes for each landscape. Murphy's Law was imposed on Saturday morning, when both target systems were accidentally destroyed. So, the green charts for Dec. 8th show our second pass, where we improved the throughput for both conversions by adding resources (one server was inadvertently left out during the first pass, and CPU data are missing from one server on the 2nd), and by increasing the parallelism based on findings on the first pass.
Here are the resulting summary text files, showing the longest running packages in each conversion. As you can see, R/3 was under 2 hours, with SCM just over 1 hour.
R/3 Development Unicode conversion - 2nd pass
Top 10---------------------------------------------------------------------
| Packages | Runtime (2007-12-08 14:15 - 2007-12-08 16:01) |
|-------------------------------------------------------------------|
| REPOSRC |EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEIII|
| DBTABLOG |EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEIIIIIII|
| EDIDS |EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEIIIIIIII |
| SAPAPPL2 |EEEEEEEEIIIIIIIIIIIIIIIIIIIIIIIII |
| EDI40-4 |EEEEEEEEEEEEEEEEEEEEEEEEEEEIII |
| SAPAPPL0 |EEEEEEEEEIIIIIIIIIIIIIIIIII |
| RFBLG |EEEEEEEEEEEEEEEEEEEEEEEEI |
| SOFFCONT1 |EEEEEEEEEEEEEEEEEEIIIIII |
| CDCLS |EEEEEEEEEEEEEEEEEEEEEI |
| EDI40-1 |EEEEEEEEEEEEEEEEEEEEEEI |
SCM Development Unicode conversion - 2nd pass
Top 10---------------------------------------------------------------------
| Packages | Runtime (2007-12-08 14:37 - 2007-12-08 15:23) |
|-------------------------------------------------------------------|
| REPOSRC |EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEIIII|
| SAPAPPL0 | EEEEEEEEEEEEEIIIIIIIIIIIIIIIIIIIIIII |
| SAPAPPL2 | EEEEEEIIIIIIIIIIIIIIIIIIII |
| SAPSSEXC | EEEEEEEEEEEEEEEEEEEIIII |
| SAPAPPL1 | EEEEEEEEE IIIIIIIIIIIIII |
| SAPNTAB | EEEEEEEEEEEEI |
| DOKCLU | EEEEEEEEEI |
| SEOCOMPODF | EEEEEEEIIII |
| D010TAB | EEEE IIIIII |
| DYNPSOURCE | EEEEEEII |
In both systems, the REPOSRC table was the longest running, which makes a little sense, as that contains all ABAP source code, including every change since the dawn of time, not to mention every temporary object ever created. This won't be true for the rest of the landscape, particularly since we have tables that are bigger than either of these systems (note E=Export, I=Import).
Database sizes (from transaction DB02)
DEV| Date | Values | Size/kb | Free/kb | %-Used | Tables - Total | Size/kb | Indices - Total | Size/kb |
|---|
| 12/09/2007 | Total | 223,800,320 | 89,538,048 | 60 | 37,901 | 71,443,968 | 45,138 | 39,200,064 |
| 12/02/2007 | Total | 243,010,560 | 99,737,664 | 59 | 37,573 | 84,106,368 | 44,717 | 49,617,536 |
| 11/25/2007 | Total | 216,383,488 | 72,981,504 | 67 | 37,573 | 84,057,920 | 44,717 | 49,568,768 |
SCD
| Date | Values | Size/kb | Free/kb | %-Used | Tables - Total | Size/kb | Indices - Total | Size/kb |
|---|
| 12/09/2007 | Total | 93,171,712 | 55,225,344 | 41 | 22,162 | 16,953,152 | 28,899 | 11,706,624 |
| 12/02/2007 | Total | 140,319,744 | 99,808,896 | 29 | 21,997 | 20,585,152 | 28,758 | 16,523,008 |
| 11/25/2007 | Total | 103,451,648 | 62,949,312 | 40 | 22,000 | 20,580,288 | 28,755 | 16,520,576 |
What is noteworthy on the size charts are the increase in total database sizes prior to the conversion -- this is a result of provisioning surplus temporary and rollback space on the source system. Both systems saw space reduction post-Unicode. It doesn't quite look like the R/3 system shrank, since it has about 8GB more allocated space, but percent used dropped from 67% to 60%, and both index and tables are smaller. Again, the excess space is in temp and/or undo.
Rough math shows we hit conversion rates around 100GB per hour on these systems. Production will have more CPUs, but the same speed. Our prior conversions with 3TB systems were about 12 hours => 250 GB/hour. My goal for the 6TB conversion in February will be 400GB/hour, or a 15 hour database downtime.
Surprises
Probably the biggest unexpected work so far has been untangling environment scripts needed to go from Oracle 9 to Oracle 10. We are not upgrading the SAP kernel so that build is still on the Oracle 9 OCI libraries, meaning it is not happy with Oracle 10 libraries. The method used to create client homes is messy, and we probably should have tested the Instant client more before trying it.
Another surprise was some bad packed decimal data in the S025 table. To have the conversion complete, we needed to pull those rows out of the table. Somehow spaces were in the columns instead of the expected digits. The only SAP note I found for this (700486  ) talks about DB2/390 conversions, referring to note 339932 which I can't read. I think the relevant report is SDBI_CHECK_ORANUMBERS. For our quality and production conversions, this means another step prior to the conversion weekend, to look for any corruption, similar to what we did for orphaned CDCLS records.
) talks about DB2/390 conversions, referring to note 339932 which I can't read. I think the relevant report is SDBI_CHECK_ORANUMBERS. For our quality and production conversions, this means another step prior to the conversion weekend, to look for any corruption, similar to what we did for orphaned CDCLS records.
One thing we should have know beforehand is that Oracle 10 has a parameter to deal with space issues (resumable session) but we had to use a logon trigger to do this in 9.
Future trials
We used the default SAP table splitting method, which scans the primary key and then calculates where to split in roughly equal buckets. For our next conversions, we will use the "ROW ID" method, which leverages Oracle database internal architecture to more quickly create the package split points. Any time savers translate to sleeping opportunities, meaning fewer mistakes by tired staff!
Live Cache
I need to research details on our Live Cache conversion. There were surprises during the set up but I wasn't watching the conversion, so stay tuned for the next episode!
