Execute conversion of logical system names (BDLS) in short time and in parallel - Intermediate During Homogeneous system copy from PROD to QAS environment, the most important step is to “convert logical system (LOGSYS) names” using transaction code BDLS. This conversion usually takes long time for large size database tables. This Weblog steps will help you in completing BDLS in less time. The final execution times differ a lot, following these steps we are able to run BDLS conversion in 6hrs which used to run for 18hrs for single logical system conversion run for the size of 12TB.
Step 1 - Create BDLS Indexes for bigger tables for columns LOGSYS:
Step 1.1: Find out what are the largest tables in your production system which are taking long time for BDLS conversions and list them out with LOGSYS (Logical system) fields. Example: It is very easy to find out LOGSYS fields for large tables, if you have any old BDLS run logs you can see the fields as follows. Run SLG1 and enter object “CALE” and you will see this in the following screen shot - For Table EBKPF the logical system field is referred as AWSYS. 
The following shows few large size tables with logsys field details.
| Table name | Columns for index |
|---|
| BKPF | MANDT
AWSYS |
| CE11000 | MANDT
COPA_AWSYS |
| COBK | MANDT
LOGSYSTEM
AWSYS |
| COEP | MANDT
LOGSYSO
LOGSYSP |
| COES | MANDT
AWSYS |
| COFIS | RCLNT
LOGSYS
RLOGSYS
SLOGSYS |
| GLPCA | RCLNT
AWSYS
LOGSYS
AWSYS |
| GLPCP | RCLNT
AWSYS
LOGSYS |
| GLPCT | RCLNT
LOGSYS |
| MKPF | MANDT
AWSYS |
| SRRELROLES | CLIENT
LOGSYS |
Step 1.2: Create custom b-tree (default) indexes for the above described (large tables) tables with columns described. What are the sizes for Special index would be? The index size will not large for an example: for table CE11000 size of 230GB, your special index size would be close to 20GB.
Create index for table CE11000 and example (Oracle Database) sql is as follows: CREATE INDEX SAPR3."CE11000~Z1" ON SAPR3.CE11000 (MANDT, COPA_AWSYS) NOLOGGING TABLESPACE PSAPBDLSI / ALTER INDEX SAPR3."CE11000~Z1" NOPARALLEL / ANALYZE INDEX SAPR3."CE11000~Z1" ESTIMATE STATISTICS SAMPLE 2 PERCENT / exit; Notes: 1)You might need additional temporary database space to support special indexes. 2)Even though most of these tables are transactional tables, the standard BDLS program will go though entire table to check for conversions. So, the creation of indexes will help in reducing the total run time.
Step 2 - Run BDLS with high commit number and run conversion in parallel: The following describes how to run BDLS for table groups and run them in parallel. For all long running BDLS runs during post processing of system copies this method will be used to reduce the amount of down time.
The documentation is developed for the following selections:
BDLS running in system : TST and Client : 300
Source Logical System : SAPPRD300
Target Logical System : SAPTST300
After the BDLS index creations are done, please follow the parallel character runs for BDLS conversions. (26 alphabets and 1 run for NOT EQUAL to A* to Z*) Please start the BDLS run for all the following 27 combinations and please use the step 2.4 table as checklist. Please make sure you have 27 to 30 BTC work process available for this run. If not please increase the background work process in RZ04 and trigger/activate the same in RZ03. Step 2.1: Start transaction code BDLS and enter the required old/new logical system names and unselect other options “Test Run” and “Existence Check on new names in tables”. Please enter tables to be converted choice as A* and execute the BDLS run in the background. Number of entries per commit: (1million is default) Please enter the value as 10 millions(10,000,000) Note: The value in the field Number of entries per Commit is only relevant for the actual conversion (not for the test run). To improve performance, you should choose a value as high as possible, provided that the database roll/Undo area is large enough.

Please execute t-cd: SM37 to make sure the job RBDLS300(the program differs for WAS640) started for A* variant.

Step 2.2: Please repeat the above process of running BDLS for all other tables like B*, C*…..till Z* in the background. (In parallel)

Step 2.3: After you trigger all 26 jobs for all A* to Z* tables, please run the last table set for Not Equal to ranges A* to Z* which covers all “/” tables and others.
Please select the tables to be converted and enter the following:

Please click enter and verify the old/new logical systems and other options.
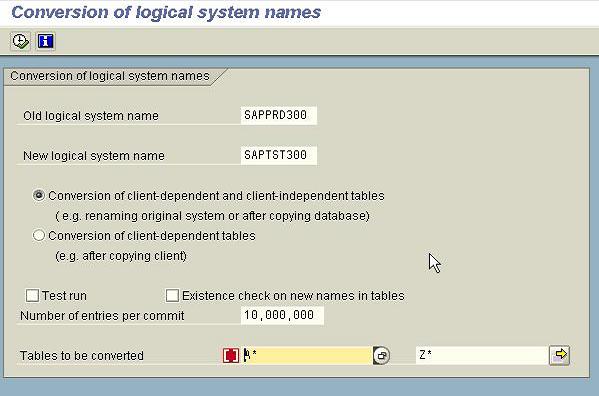
Now please trigger the run in background.
Step 2.4: Verification for jobs and SLG1 - object CALE logs: Please make sure you have total 27 jobs (T-cd : SM37) are running/completed for BDLS report.

Please verify SLG1 object CALE logs for each run and make sure in the log tables are converted for logical system names.
Please see following, in this example D* tables are converted and others marked as “<<” for not mapping.

When monitor the other logs you may need to refresh the SLG1 screen for the newly created logs. Please run t-cd : /nSLG1 - CALE - Execute. Please do use reference numbers, which you have completed analysis on last log.
| Serial no. | Tables to be converted | Status | Job status | SLG1 status |
|---|
| 1 | A* | Completed | Successful | No errors |
| 2 | B* | Started | Running | In Process |
| 2 | C* | | | |
| 4 | D* | | | |
| 5 | E* | | | |
| 6 | F* | | | |
| 7 | G* | | | |
| 8 | H* | | | |
| 9 | I* | | | |
| 10 | J* | | | |
| 11 | K* | | | |
| 12 | L* | | | |
| 13 | M* | | | |
| 14 | N* | | | |
| 15 | O* | | | |
| 16 | P* | | | |
| 17 | Q* | | | |
| 18 | R* | | | |
| 19 | S* | | | |
| 20 | T* | | | |
| 21 | U* | | | |
| 22 | V* | | | |
| 23 | W* | | | |
| 24 | X* | | | |
| 25 | Y* | | | |
| 26 | Z* | | | |
| 27 | Not Equal to A* to Z* | | | |
Step 2.5: Here attached the sql traces/cost for table CE11000 (230gb size table) for bdls conversion with index and without index. With out index the BDLS conventional run completed in 7hrs and with index it completed in 2mins. BDLS Run with out index for table CE11000:  BDLS Run with index CE11000~Z1 for table CE11000:
BDLS Run with index CE11000~Z1 for table CE11000:  Step 3 - Drop special indexes:
Step 3 - Drop special indexes: After Successful conversion of logical systems you can drop special indexes created as per step 1.
Example sql commands: DROP INDEX SAPR3."CE11000~Z2" / DROP INDEX SAPR3."CE41000~Z2" / Notes: - For tables like X*, Y* you will not see any conversion, but log exists with no tables marked. These tables are skipped in the log due to no X*, Y* tables has fields like LOGSYS configured and no conversion required.
- Some times based on your system landscape, in QA system you may need to run few other BDLS conversions for BW, Event manager, SRM systems. Please repeat the above steps for second conversion. Example: R3 TST system refreshed using R3 PRD: the Primary R3 conversion is from SAPPRD300 to SAPTST300 and Second conversion for Event manager is from SAPEVP110 to SAPEVQ110.
In Summary:
The above described steps are in very detail, Steps 2 and 3 take very less time and step 1 might take little long time to execute and this depends up on your SAP database size. All together the total amount of time it takes to complete BDLS is less than what you usually run with standard procedure. The BDLS runs takes about 16hrs to 18hrs for VLDB (very Large Database systems) size of 13TB. With above procedure you will be completing this in 5 to 6hrs including index build time. Find bigger tables in your system and create BDLS index before you start running BDLS, Run BDLS for single tables in parallel with higher commit number, verify logs for successful conversion, verification of all table runs and Drop BDLS indexes which were created as part of step 1.
I hope this helps you in completing your BDLS runs in less time. I used to run 4 different BDLS conversion runs for single system in 70 to 72hrs before and now with above 3 steps it only takes 8 to 10hrs for VLDB system size of 12TB.
