In my previous blog of this DataMining blog series ( jeyakumar.muthu2/blog/2005/11/23/data-mining-using-apriori-algorithm-in-xi-150-part-i ), I had explained the theoretical implementation steps of APriori algorithm. In that, the first step is Candidate Generation process. Before going to this process, the input flat file should be converted into a XML file using File Content Conversion.
What is Candidate Generation process?
Well, this process can be defined in two sections. These sections can be differentiated by the structure of the input file. Because this process has two different input files. You can see this in my previous blog’s diagram.
In the first section, it will get the input XML file, which is generated by the File Content Conversion technique. This section will read this input file and generate the output file, which should have unique candidates only. Unique candidate means only one entry for each candidate, no duplication of the candidates is allowed. The output file is called as First Candidate Itemset.
Now we will see the file structures of this section.
Input File

Output File

Message Mapping

In this message mapping, you have to do two important things. First one is Context Change, which is pointed out in the previous diagram. Next one is the properties of the node function “sort”. This is mentioned below.

Normally, in this algorithm all the candidates should be processed in the lexicographical order only. So that, we are choosing the Comparison type as “Lexicographical” in the sort node’s properties.
Java Function

Now the business logic comes into the picture. This should return the unique candidates.
Code Area
Next, create the interface mapping using the abstract interfaces to use in the Integration Process.
In the second section, it will get the input file from Candidate Pruning process. This part also will produce unique candidates. But the difference is it will produce the combinations from the given input candidates. In the DataMining world, they will call as N-th Candidate Itemset according to their level.
Now, we will see the file structures of this section.

Output File

Message Mapping

In this mapping also change the “sort” node properties as I mentioned before.
Java Function
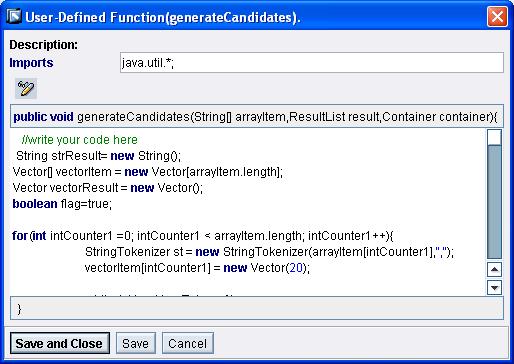
Here is the business logic… this will produce the unique candidate combinations from the input N-th Candidate Itemset.
Code Area
Then, create the interface mapping using the abstract interfaces to use in the Integration Process.
Now, we will see the Integration Process.
Integration Process

As explained earlier, this Candidate Generation process has to be carried out in two different ways depending on the input file structure.
So the Integration Process has got two seperate branches to process the input file. A Fork step is used for this purpose. Both the branches of the fork step have got a receive step corresponding to a particular structure of input file ( input interface ).So depending on the input file that arrives, the corresponding receive step ( i.e. the entire Branch ) is activated and subsequent transformation is performed. At any point of time, only one Branch of the fork is activated and the other never gets triggered. So, a container operation is performed after the transformation step and this operation is used to terminate the fork step.
Input file for the First section

Output file for the First section

Input file for the Second section

Output file for the Second section

In my next blog of this DataMinig blog series, we will see the practical implementation of the Support Calculation process and the Candidate Pruning process.
