I recommend the readers to go through Message Mapping Simplified - Part I before marching ahead with this blog. There was a delay in blogging the Part II due to my project schedules. I still remember my school days where I always loved to solve the most difficult and confusing problems encountered in my favorite subject “Maths”. The same used to happen with me in computers while in graduation. I never scored excellent percentages in my report cards but I used to be the first one to raise a hand with a solution whenever my teacher declares the problem is not easily solvable. I don’t sleep until that is solved and have been successful till date.
The most irritating part in the message mapping is to understand the node functions. So I will try to explain about it, which might be useful for any new XI developers to play around. I can’t assure that explanation is 100% correct as I am trying to explain the way I understand. I am able to solve any complex message mapping that is encountered so far and thought of putting across my understanding to sdn. Experienced professionals can excuse if the understanding is already there!
Types of useful node functions:
1.removeContexts
2. SplitByValue
3. collapseContexts
4.copyValue (not a node function)
5.createIf
6.exists
7.useOneAsMany
Here I tried explain all the node function with one real time example .This kind of scenario is very frequent when dealing with idocs and flat files.
Brief about Transformation Logic : Material Master Idoc is sent with one header and multiple items which has to be written to a target file containing combination of header and line item details. I didnot use the actual idoc structure for better clarity.

Notice the occurrence field in both the source and target format. I have to generate target header nodes equal to the number of occurrences of item in the source node. So I map it as shown below.

I chose the transformation logic such that all the node functions are used.
1.removeContexts- “There is absolutely no difference between my children or grand children or great grand children”. Material Group is sent in the item node of the source idoc but I want it in the header node of the target idoc. So I need to fool the mapping runtime that Material Group is coming in the header node of the source. removeContext exactly does that.

We are making the grand child “Material Group” as a child of the header node and fooling the mapping runtime to parse accordingly.
2.SplitByValue- “I need a different parent for every instance of me”
I will try to explain the function with the same mapping as readers can correlate well. Each instance of Itemno in the source structure should generate a target itemNo and item under a different instance of the header node in the target.
As we can observe that occurrences of item in the source and target structure are different we cannot map the elements of the item node directly. We use splitbyValue to achieve the same.
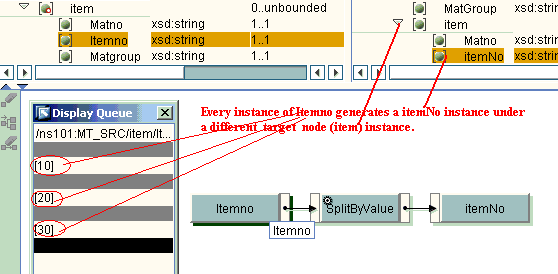
splitbyValue generates Itemno in the target for every value of itemNo in the source under a different target instance of item node which in turn belongs to a different header node.
3.collapseContexts- “ There is just a slight difference between my children or grand children or great grand children”. Similar to removeContext but context change is replaced with “”. If we need to create empty tags in the target for every context change in the source we can use it. I did not find it useful so I don’t like to explain in detail.
4.copyValue-“How many ever times I occur I am copied just once”. This is not a node function but I am explaining it as it is used very frequently in real-time.
Let us take an instance of material group, which can occur as many times as the item node. But since we are mapping it to the header in the target node I just want to copy the first occurrence of material group and map it to the header node. copyValue exactly does that.

5.createif-“I have a criteria for existing”. It is used when you want to create target node or element based on some condition.

We need to generate the material type tag in the target xml for only pencil material. This can be done using createIf.
6. exists- “Do I exist?”
This is the most frequently needed when mapping idoc structure to file structure. Lot of times we come across a scenario where the fields (occurrence=0) are not mandatory in the idocs are not populated in the source xml and they are required in the target xml (occurrence =1) which gives a mapping run time exception that target element cannot be created. We can handle the error by checking whether the source tag exists and if it does not we can pass an empty value, which generates the required target field.
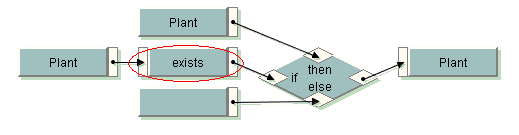
Material Plant is optional in the source structure but the target field expects a blank if idoc does not populate the material group field. exists takes the head ache.
7.useOneAsMany- ”I occur only once but have to be replicated as many times as my siblings or nephews occur”.
This is really a nice function, which will be used very often. As shown in the figure above the maximum occurrence of the header node in the source is 1 and the target is unbounded. So we have only one occurrence of material description, which has to be replicated for every line item. Bingo! useOneAsMany exactly does that! Check it out.

I assume that this information is up to the expectations of the readers who are eagerly waiting for the part-II .I provided a real time example to elucidate the concepts in a better fashion.
