Introduction
There have been recent discussion in the BSP forum on BSP and Excel. I would like to take this one step further and discuss how to do this same download, but with the data in Unicode.
The example code in this thread works great until you hit one situation. If you have a Unicode or MDMP SAP system and you are downloading data from more than one code page or from a different code page than the default codepage of the OS that the client is running, you will have a problem. The data stream that is sent to Excel will be encoded with the default codepage for the logged on language and it will then corrupt any characters from another code page.
Example
To give you a concrete example I will tell you about our system. We have English and Polish both installed in our system (using MDMP we have two code pages Latin-1 for English and Latin-2 for Polish). My Windows XP client is Unicode capable as is Microsoft Office. However your pc also has to work in a single non-Unicode code page when dealing with non-Unicode data. This is normally set by the country version of the OS you are running (In Windows XP you can switch this value in the Region Settings). My PC for instance is US based and therefore runs English (Latin-1) as its default codepage. I then run a BSP page logged on to the WebAS in Polish. I need to download a report with Material Descriptions that are in Polish. However the download from SAP by default will be in Polish (latin-2) and my PC and Excel won't understand it since they are expecting English (Latin-1). As you can see from this screen shot, what I end up with is quite a mess. The BSP output is on the top and is formatted correctly. However the Excel display on the bottom has many incorrect and corrupted characters:
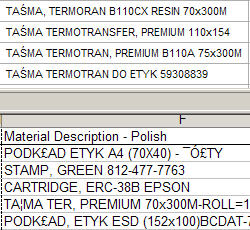
Looking at MS Excel
I would like to give you some code samples that will expand on those in the given Forum posting. I want to stress that these samples will work even in a non-Unicode SAP system. I have tested them on WebAS 620. The first thing we have to understand is what kind of Unicode file does MS Excel want. After doing a little research, I found out that Excel expects a UTF-16 encoded file (evidently all the Microsoft Office tools use UTF-16 when saving files in their primary format) with a byte order mark of Little Endian. If UTF-16 and Byte Order Mark (BOM) are unfamiliar, I suggest some light reading on the Unicode Home Page.
I wanted to verify this information I had found on the web. I opened Excel and typed in some Polish national characters. I then saved my spreadsheet as Unicode Text. This creates a tab-delimited text file in Unicode format. I then opened the file in a Hex Editor. Sure enough, there was my UTF-16le (Little Endian) Byte Order Mark - FF FE - right at the beginning of the of the file.

Possible BOM Values
For reference the following are the possible values for the Byte Order Mark:
| Bytes | Encoding Form |
|---|
| 00 00 FE FF | UTF-32, big-endian |
| FF FE 00 00 | UTF-32, little-endian |
| FE FF | UTF-16, big-endian |
| FF FE | UTF-16, little-endian |
| EF BB BF | UTF-8 |
ABAP Code Changes
Now we are ready to start making changes to the ABAP code from our BSP examples. The first thing we need to change is the application type string.
Old Code
APP_TYPE = 'APPLICATION/MSEXCEL'.
New Code
app_type = 'APPLICATION/MSEXCEL; charset=utf-16le'.
With this change we have now set our output character set to UTF-16 Little Endian. The call to SCMS_STRING_TO_XSTRING will now use UTF-16le as the destination format as it converts our source string to our output binary string:
call function 'SCMS_STRING_TO_XSTRING'
exporting text = l_string mimetype = app_type importing buffer = l_xstring.
For Reference the SAP internal Code page numbers are 4102 for utf-16be, 4103 for utf-16le, and 4110 for utf-8. These can be found in table TCP00A or by calling function module: SCP_CODEPAGE_BY_EXTERNAL_NAME.
That was actually quite easy. Now we have our output formatted as Unicode Text Tab Delimited. We just need to add the Byte Order Mark to the beginning of the binary string:
concatenate cl_abap_char_utilities=>byte_order_mark_little
l_xstring into l_xstring in byte mode.
Here we used the wonderful little class CL_ABAP_CHAR_UTILITIES. It already has the Byte Order Marks for UTF-8, UTF-16be, and UTF-16le defined for us.
Closing
As you can see in this final screen shot, out output in Excel now matches what we saw on the screen in BSP:

Full Code
Here is the complete code sample taken from the original forum posting and adjusted with the changes I have suggest here. Just in case the original forumn posting ever becomes unreachable. Special thanks to Suresh Babu for originally posting this code to the BSP forumn.
***ITAB contains my data so..
LOOP AT ITAB INTO WA.
CONCATENATE L_STRING WA-PARTNER WA-ADR_KIND WA-ADDRNUMBER
CL_ABAP_CHAR_UTILITIES=>CR_LF
INTO L_STRING SEPARATED BY SPACE.
ENDLOOP.
APP_TYPE = 'APPLICATION/MSEXCEL; charset=utf-16le'.
call function 'SCMS_STRING_TO_XSTRING'
exporting text = l_string
MIMETYPE = APP_TYPE
IMPORTING BUFFER = l_xstring.
* Add the Byte Order Mark - UTF-16 Little Endian
concatenate cl_abap_char_utilities=>byte_order_mark_little l_xstring
into l_xstring in byte mode.
response->set_header_field( name = 'content-type' value = APP_TYPE ).
* some Browsers have caching problems when loading Excel Format
response->delete_header_field( name = if_http_header_fields=>cache_control ).
response->delete_header_field( name = if_http_header_fields=>expires ).
response->delete_header_field( name = if_http_header_fields=>pragma ).
* start Excel viewer either in the Browser or as a separate window
response->set_header_field( name = 'content-disposition' value = 'attachment; filename=webforms.xls' ).
* finally display Excel format in Browser
l_len = xstrlen( l_xstring ).
response->set_data( data = l_xstring length = l_len ).
navigation->response_complete( ).
