
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- BSP In-Depth: Writing an HTTP Handler
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-30-2003
10:19 AM
In the last few weeks I was asked the same question twice: “How can I access my pictures that are stored somewhere in a database?” In one case the pictures were already stored in the database, and in the other it was under consideration. However, in both cases the problem was the red line between the browser and the picture stored somewhere in SAP Web Application Server (Web AS).
There are many techniques to store pictures in Web AS. This complex topic will be discussed in the future. For today, we would like to look at the process of writing an HTTP handler. As a test case, we’ll use an existing table of SAP icons and write our HTTP handler around it.
Problem specification: we have many pictures already stored in a database. Make them accessible in the browser. In our BSP pages, we would like to have a symbolic way to reference these pictures. What we would like to write, is something like:
<!code> <%@page language="abap"%>
<!code>
<!code>
<!code>
<!code>
<!code>
<!code> </body>
<!code>
We would expect to see this in the browser:
Very important: we are not interested in the actual picture storage and the few lines of code written to use the content from the database. We want to concentrate on aspects such as URL generation and the handling of the incoming HTTP request.
Exploring the ICF Tree
A Web server is like a large shopping center: thousands of incoming customers, all asking for a specific shop. Only here, we have thousands of incoming requests, all asking to be processed. The problem is how to dispatch each HTTP request to the correct handler.
This is the work of the Internet Communication Framework (ICF). The ICF takes the URL from the HTTP request and splits it into tokens. The tokens are used to route the HTTP request through a tree of services.
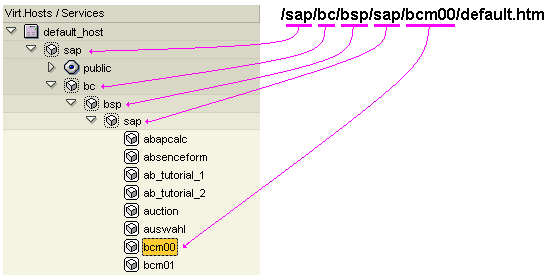
Zero or more HTTP handlers can be on each node. The handlers are processed in sequence, until one handler signals that it has processed the request completely. After that, the HTTP response is returned to the browser. A node does not require a handler. If no handler is found on a specific node, the next node in sequence is checked. Important: HTTP handlers are processed from the root downwards, as they are encountered.
For example, for the above BSP application, the nodes “sap“ and “bc” have no handlers. The node “bsp” contains the BSP runtime handler. It will look at the incoming HTTP request and completely process it. Because the BSP runtime indicates to ICF that the request has been fully processed, no further searching is done through lower levels of the ICF tree.
For BSP, the decision was made that each BSP application must have its own node inside the ICF tree. This allows the ICF to also support additional functionality for the individual BSP applications. Typically, you can activate (or deactivate) a specific BSP application via its corresponding ICF node. It’s also possible to configure user logon information for the specific BSP application in its ICF node.
The usual problem of one global namespace, and how to segment it, also applies to the ICF tree (or effectively applies to the domain of all possible URLs). Here, the “agreement” (that is enforced), is that all SAP development will be within the “/sap” sub-tree. At the next level, the “bc” node represents SAP basis development. Similarly, it is expected that customers will also do their own Internet development under a “/customer” namespace.
All valid URLs need not be listed in the ICF tree. It’s possible to have a URL “/test/A” and “/test/B”, with only the “test” node defined in the ICF tree. The handler for the “test” node is activated to process the HTTP request.
For each handler, it’s important to know what part of the URL was used to find the handler, and to have the rest of the URL available to make its own decision on what actions it wishes to take. ICF makes this information available in special header fields. (These header fields are added to the incoming request by ICF, and are not actually part of the original request.)

The three most interesting fields are:
~request_uri: This is the complete URL requested from the browser.
~script_name: This is the first part of the URL that was used to navigate through the ICF tree until this specific handler was found.
~path_info: The rest of the URL that has not yet been used to resolve a handler. The handler uses it to decide what action to take.
The last part of the puzzle is what defines an HTTP handler. It’s a normal ABAP class, which implements the interface IF_HTTP_EXTENSION with one method HANDLE_REQUEST. Once ICF has found a node that contains a handler (class), it is instantiated and called to process the request. As an input parameter, the method gets a server object, which is effectively a wrapper object containing the HTTP request and response objects.
First Steps
Now that we have explored the ICF tree, it’s time to make our mark. First, we must have an HTTP handler class.
We create a class CL_IMAGE_HANDLER and specify that it implement the interface IF_HTTP_EXTENSION. For the HANDLE_REQUEST method, we have:
<!code> METHOD if_http_extension~handle_request .
<!code>
<!code> if_http_extension~lifetime_rc = if_http_extension=>co_lifetime_keep.
<!code> if_http_extension~flow_rc = if_http_extension=>co_flow_ok.
<!code>
<!code> server->response->set_cdata( 'Hello World!' ).
<!code> server->response->set_status( code = 200 reason = 'OK' ).
<!code>
<!code> ENDMETHOD.
We set the lifetime return code to inform ICF that after our handler has been processed; it should be kept, and reused if possible. (Note that lifetime has no relationship to session management. It is a slightly unfortunate choice for a name.) The flow return code informs ICF that we have finished processing the request, and written a complete response.
The last two lines are the classic “Hello World!” for Web servers. Note that we do not set any of the content specific headers (bad programming!), and rely on the default behavior of ICM.
With this, we have a handler class that will respond with valid HTML coding when called,.
We must now decide where we wish to place this handler in the ICF tree. If we keep the namespace concepts in mind, as an example I must choose “/sap” because I work for SAP, plus “bc” as I am in the basement. Thereafter, complete freedom. So let’s settle for “/sap/bc/images”.
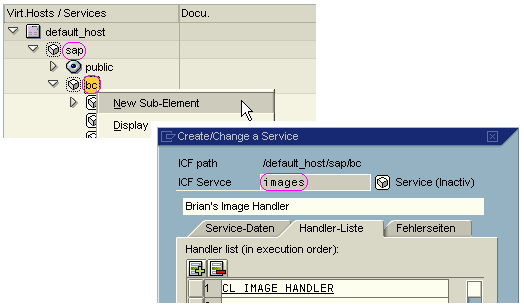
With this, we have defined a new HTTP handler. We activate the node and use the context menu to start a test for this node.
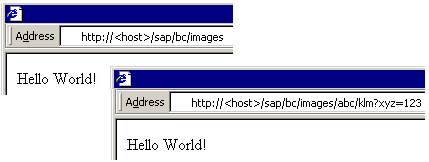
We can see that our handler works for all types of URLs that start with “/sap/bc/images”. This part of the URL (script_name) is used to find the handler. The rest of the URL (path_info) is ignored by the handler at this time.</p>
Defining the URL Syntax
There are two ways that URLs can be defined. Either use the rest of the URL to contain additional information (for example /sap/bc/images/NAME), or use parameters on the URL to define the image required (for example /sap/bc/images?name=NAME). Both techniques are similar, but the first is more elegant (beauty lies in the eye of the beholder!), and slightly shorter.
Initially, we required a method CL_IMAGE_HANDLER=>URL to handle all problems. We would just write the URLs directly onto the page, but this is not flexible for future changes and opens the possibility of typing mistakes. The method call is checked by the compiler.
We’ll add a new static public method URL( ) to the class, with “name” as the import parameter, and “url” as the return parameter. Both are type STRING. The complete source code is:
<!code> method URL.
<!code> CONCATENATE '/sap/bc/images/' name INTO url.
<!code> endmethod.
You would be tempted to consider appending ‘.gif’ onto the URL to help the browser determine what type of image it’s loading. However, this is not required. The browser will use the Content-Type header to determine the image type.
If we run our test BSP page from above, we see in the source:
<!code>
<!code>
<!code>
<!code>
<!code> </body>
<!code>
Unfortunately, the handler keeps answering with “Hello World!” for each image request.
Writing the Handler
The HANDLE_REQUEST method can be broken into four distinctive parts, each part less than 10 lines of code!
<!code> METHOD if_http_extension~handle_request .
<!code>
<!code> * Inform ICF to "keep" (reuse) this handler, and that we answered the HTTP request
<!code> if_http_extension~lifetime_rc = if_http_extension=>co_lifetime_keep.
<!code> if_http_extension~flow_rc = if_http_extension=>co_flow_ok.
Inform ICF that it may reuse this handler if possible. Also set the flag that this handler has finished processing the HTTP request. Due to the URL( ) method, we expect that most HTTP requests will be correct. If any error occurs, we just raise an exception.
<!code> * Determine image name from URL script_name/path_info (= image_name)
<!code> DATA: name TYPE string.
<!code> name = server->request->get_header_field( name = if_http_header_fields_sap=>path_info ).
<!code> TRANSLATE name TO UPPER CASE.
<!code> IF STRLEN( name ) >= 1 AND name(1) = '/'.
<!code> SHIFT name LEFT.
<!code> ENDIF.
Next, we must determine the required image. The ~path_info header field contains the part of the string that has not yet been used by ICF. (Keep in mind that the beginning of the URL was used to find this node in the ICF.) The string is determined and massaged a little (upper case, strip leading ‘/’-character).
Up to now, all code has used relatively common handling of HTTP requests. Now a little application logic is required to determine the GIF image, and load it. Starting this block of code, we have the name of the image as input and expect an XSTRING containing the gif image as output. The exact storage mode and location are not relevant to our discussion here.
<!code> * Application logic
<!code> DATA: content TYPE xstring.
<!code> content = me->load( name ).
<!code> IF XSTRLEN( content ) IS INITIAL.
<!code> RAISE EXCEPTION TYPE cx_http_ext_exception EXPORTING msg = 'Invalid URL!'.
<!code> ENDIF.
Error handling is done with the usual ABAP exceptions. The ICF has an exception handler installed, and will correctly render out an error message if we should drop the ball.
<!code> * Set up HTTP response
<!code> server->response->set_status( code = 200 reason = 'OK' ).
<!code> server->response->set_header_field( name = if_http_header_fields=>content_type value = 'image/gif' ).
<!code> server->response->server_cache_expire_rel( expires_rel = 86000 ).
<!code> server->response->set_header_field( name = if_http_header_fields=>cache_control value = 'max-age=86000' ).
<!code> server->response->set_data( content ).
The last part of the handler is the HTTP response handling. First, we set the HTTP return code to 200. This is defined code to indicate that the HTTP request was processed correctly. The Content-Type header is set to indicate that this is a gif image.
Notice that the Content-Length header is not set. It will automatically be set when the HTTP response is streamed to ICM. In addition, there exists a minor “bug” that if the Content-Length is set, and the HTTP response is gzip encoded, then the Content-Length is not reset. This causes the browser to wait indefinitely on the rest of the input. This will be “fixed” in future kernel versions.
The HTTP response is flagged so that both the browser and the server will cache it. Caching the image also in ICM improves performance when the next user requests the same image.
The final statement places the content into the HTTP response. Notice that there are methods for handling both XSTRINGs (set_data and append_data), as well as STRINGs (set_cdata and append_cdata).
Maiden Voyage
The handler is finished, so let us try our test program immediately:
3 Comments
Related Content
- Joule for freestyle SAPUI5 development in SAP Build Code in Technology Blogs by SAP
- Instruction of implement-test-deploy flow for SAPUI5 plus CAP integrated with another services in Technology Blogs by Members
- Writing forecast data to Snowflake from SAP Integrated Business Planning in Technology Blogs by SAP
- Customize the ABAP Editor Theme in SAP NetWeaver in Enterprise Resource Planning Blogs by Members
- Cloud ready RAP object using legacy BAPI - Clean Core objective in Enterprise Resource Planning Blogs by Members