
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Unified Analytics with SAP Datasphere & Databricks...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-10-2023
2:56 PM
Introduction
With the announcements in the SAP Data Unleashed, SAP introduced the successor of SAP Data Warehouse Cloud, SAP Datasphere – a powerful Business Technology Platform data service that addresses the Data to value strategy of every Enterprise organization to deliver seamless access to business data. Our Datasphere has been enriched with new features thereby delivering a unified service for data integration, cataloging, semantic modeling, data warehousing, and virtualizing workloads across SAP and non-SAP data.

I am sure there will be lots of blogs that will be published soon discussing the latest offerings, roadmaps, and features. However, this blog focuses on the latest announcement related to open data partners and I am going to start by focusing on Databricks.
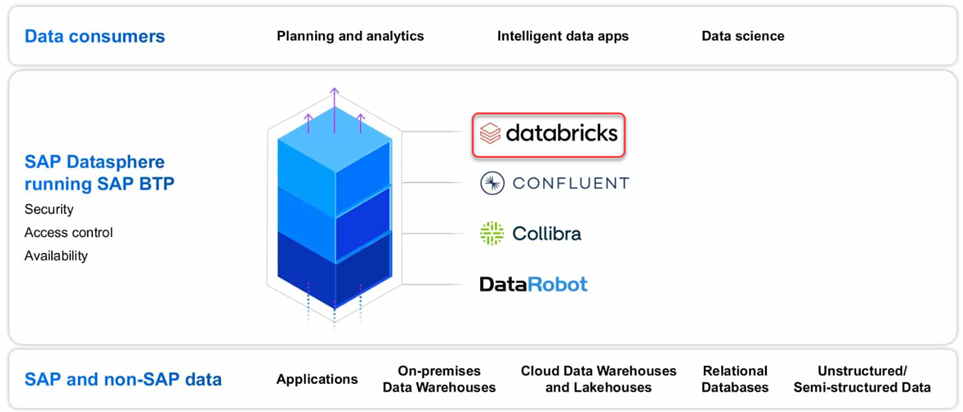
With the rise of the Lakehouse platform that combines both Data Warehouses & Data Lakes, there has been a trend with SAP customers exploring Unified Analytics Platforms or say unified environments that address different perspectives of data management, governance, development, and finally deployments of analytic workloads based on diverse data sources and formats. Previously, there is a need to replicate the data completely out of SAP environments for customers to adopt the lakehouse platform. But the current partnership with Databricks will focus to simplify and integrate the hybrid landscapes efficiently.
There was an article posted by The Register regarding the SAP Datasphere and it exactly resonated with the SAP messaging

Please note that what I am about to discuss further is the data federation scenarios between SAP Datasphere and Databricks that works as of today. There will be additional ways of integrating with Databricks in the future.
Brief Introduction to the Lakehouse Platform
In simple terms, a lakehouse is a Data Management architecture that enables users to perform diverse workloads such as BI, SQL Analytics, Data Science & Machine Learning on a unified platform. And by utilizing a combined data management platform such as lakehouse has the following benefits
- Enables Direct Data Access across SAP and Non-SAP sources
- Simplifies data governance
- Removes Data Redundancy
- Direct Connectivity to BI Tools
- Simplified security with a single source of truth
- Support for open source & commercial tooling
- Operating on multi-cloud environments and many more.
And Databricks is one such Lakehouse platform that takes a unified approach by integrating disparate workloads to execute data engineering, Analytics, Data Science & Machine Learning use cases. And as mentioned on their site, the platform is simple, open & multi-cloud. We will discuss the Lakehouse platform features and capabilities in future blogs but as mentioned before we are going to focus on a data federation scenario to access data from Databricks SQL into SAP Datasphere.
Consider a scenario where the data from a non-SAP source is continuously ingested into cloud object storage say AWS S3. Note that Databricks has an autoloader feature to efficiently process data files from different cloud storages as they arrive and ingest them into Lakehouse seamlessly. Then we utilize the delta live table framework for building data pipelines and storing the transformed data in Delta format on cloud storage, which can subsequently be accessed by Databricks SQL(DB SQL).
As referred to in the integration scenario below, SAP Datasphere will connect to Databricks SQL with the existing data federation capabilities and users can blend the data with SAP sources for reporting/BI workloads based on SAP Analytics Cloud(SAC).

Assuming you process the incoming data and persist as tables in Databricks SQL, you will then perform the following steps to establish connectivity to SAP Datasphere
Data Federation with Databricks SQL
Prerequisites
- You have access to SAP Datasphere with authorization to create a new Data provisioning agent
- Access to Virtual Machine or On-Premise system where you install Data provisioning agent.
- You have access to Databricks Clusters as well as SQL warehouse.
- You have downloaded the JDBC driver from Databricks website.
Databricks Cluster & SQL Access
As mentioned in the previous section, I assume you are already working on Databricks topics. If you are interested in getting access , you can sign up for the free trial for 14 days. Or you can sign up from the hyperscaler marketplace such as AWS marketplace for the same.

Once you login to your account, you will notice the Unified environment for different workspaces
Data Science and Engineering
Machine Learning
SQL
Navigate to workspace “Data Science and Engineering” and select the compute which you have been using for data transformation. Just to note that when we build Delta Live tables pipelines, it uses its own compute to run pipelines. We will discuss that in the later blogs.

Select the all-purpose compute to get additional information.

Navigate to the “Advanced options” to get JDBC connection details

You will find the connection details here. We need to tweak it a bit prior to connecting with generic JDBC connectors. Also, we will be connecting using personal access tokens and not user credentials.

To generate the personal access token, you can generate it from the user settings and save the token for later use.

Here is the modified JDBC URL that we will be using in SAP Datasphere connection. We need to add “IgnoreTransactions=1” to ignore transaction related operations. In your case, you will be just copying the URL from advanced options and add the parameter IgnoreTransactions as shown below
jdbc:databricks://dbc-xxxxxxxxxxx.cloud.databricks.com:443/default;IgnoreTransactions=1;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/XXXXXXXXXXXXXXXXX268/XX-XX-56fird2a;AuthMech=3;UID=token;PWD=<Personal Access Token>
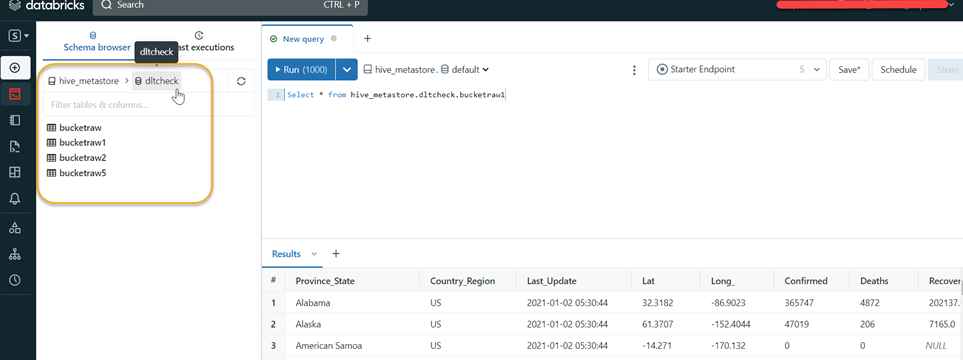
We can now navigate to Databricks SQL to see if we have the necessary schemas and tables to access. The tables were created under the schema “dltcheck”.

Data Provisioning Agent(DP Agent) Installation Instructions
I am not going the discuss the DP agent installation in detail as there are numerous articles posted on the same topic. And will be addressing the specific changes that need to be done for Databricks access.
In order to establish secure connectivity between SAP Datasphere and Databricks SQL, the Data Provisioning Agent(DP agent) has to be installed on a virtual machine and configured. For DP agent installation, you can refer to the following document. To connect the DP agent to the SAP HANA Cloud tenant of SAP Datasphere, please follow the steps mentioned in this document. Assuming all the steps were completed, the status of the DP agent will be displayed as “Connected”. In my case, the DP agent is DBRICKSNEW.

Configuration Adjustments on the Virtual Machine
Navigate to the folder <dpagent>/camel/lib and copy the jar file that is downloaded from Databricks site. Also, extract the jar files in the same location.

And navigate to <dpagent>/camel folder and adjust the properties of configfile-jdbc.properties

Change the delimident value to BACKTICK.

Save and restart the DP agent. Login to SAP Datasphere to check the status of DP agent. It should display the status as "Connected". Edit the DPagent and select the Agent Adapter “CameJDBCAdapter”

Now we should be able to connect to Databricks SQL from SAP Datasphere.
Establishing Connection from SAP Datasphere
Navigate to your space and create a new connection for the “Generic JDBC” connector

Provide any Business Name and the following details
Class : com.databricks.client.jdbc.Driver
JDBC URL : jdbc:databricks://<your databricksaccount>. cloud.databricks.com>:443/default;IgnoreTransactions=1;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/XXXXXXXXXXXXXXXXX268/XX-XX-XXXXXX;AuthMech=3;UID=token;PWD=<Personal Access Token>
Please copy the JDBC URL as such from Databricks Cluster advanced options and just add the parameter “IgnoreTransactions=1”. Setting this property to 1 ignores any transaction-related operations and returns successfully.

Provide your Databricks user account credentials or token credentials with user as token and select the Data provisioning agent that you just activated.

With the connection details and configurations done properly, validation should be successful.

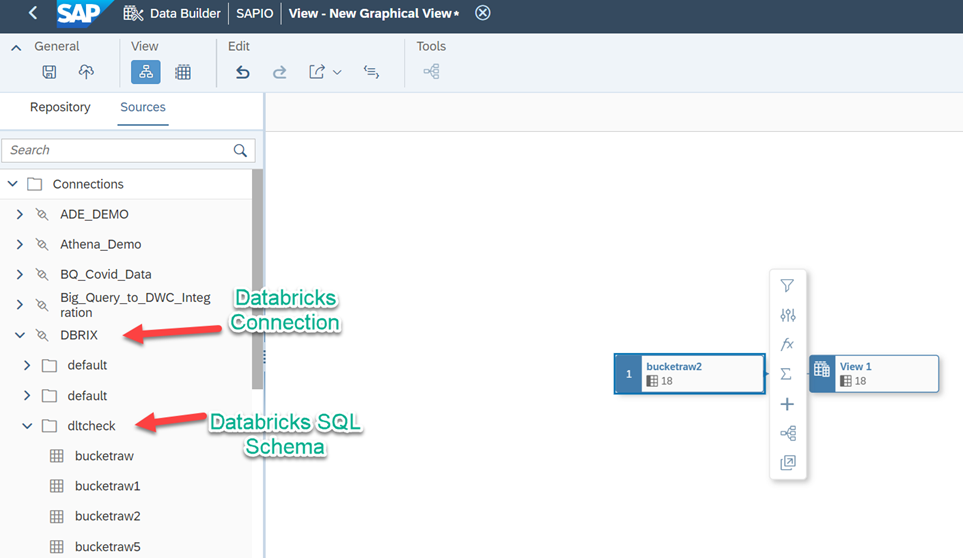
To make sure we have access to data, let’s use the Data Builder to build an analytical model that could be consumed in SAP Analytics Cloud. Navigate to Data Builder and create a new Graphical View

Navigate to Sources->Connections->Databricks("Your Business Name For Generic JDBC Connection")->"Databricks Schema". You will find the list of tables under the schema "dltcheck"
Here is the Databricks SQL Access for the same schema "dltcheck"
Select the data with which you wanted to build the Analytical model. In my case it is bucketraw1, added some calculated columns, aggregated the necessary data, and exposed the relevant columns as the Analytical model “Confirmed_cases”. And the data preview of the model shows the corresponding records too.

This model could be consumed in SAP Analytics Cloud for reporting.
Troubleshooting Errors
1. If you do not see the connection validated, then there are two options to troubleshoot. Either we can use the generic log files from DP agent to identify the issue or add the log parameters in JDBC URL and collect those specific errors. If you face validation issues, then add these parameters in the jdbc url.
jdbc:databricks://<youraccount>.cloud.databricks.com:443/default;LogLevel=5;LogPath= <foldername>;IgnoreTransactions=1;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<SQLPath>;AuthMech=3;UID=token;PWD=<token>Log Level – 5 which means enable logging on the DEBUG level, which logs detailed information that is useful for debugging the connector
Logpath – This will be available in the following path /usr/sap/<dpagentfolder>/
The log path can be found on the linux VM and it will generate the specific log files

2. If you see some errors related to mismatched input, then please adjust the camel jdbc properties as mentioned in DPAgent Installation Instructions. The “DELIMIDENT” value should be set to “BACKTICK”.
2022-12-19 16:31:57,552 [ERROR] [f6053d30-7fcd-436f-bed8-bf4d1358847788523] DefaultErrorHandler | CamelLogger.log [] - Failed delivery for (MessageId: 2567788B8CF359D-0000000000000000 on ExchangeId: 2567788B8CF359D-0000000000000000). Exhausted after delivery attempt: 1 caught: java.sql.SQLException: [Databricks][DatabricksJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: org.apache.hive.service.cli.HiveSQLException: Error running query: org.apache.spark.sql.catalyst.parser.ParseException: mismatched input '"FUNCTION_ALIAS_PREFIX_0"' expecting {<EOF>, ';'}(line 1, pos 33)
== SQL ==
SELECT SUM("confirmed_cases") AS "FUNCTION_ALIAS_PREFIX_0", SUM("deaths") AS "FUNCTION_ALIAS_PREFIX_1", "covidsummarygcs$VT"."county_name" FROM "default"."covidsummarygcs" "covidsummarygcs$VT" GROUP BY "covidsummarygcs$VT"."county_name"3. If you see the communication link failure, then the IgnoreTransactions parameter has not been set in your JDBC URL.

As mentioned before, the data federation is enabled through JDBC connector as of now . But things will change with additional connections in the future. Hopefully this helped you in understanding the Data Federation capabilities with Databricks. Please do share your feedback. In case of connection issues, feel free to comment, and will try to help you out.
- SAP Managed Tags:
- SAP Datasphere,
- SAP HANA Cloud,
- Big Data,
- SAP Business Technology Platform
Labels:
19 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
117 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
75 -
Expert
1 -
Expert Insights
177 -
Expert Insights
358 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
15 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
398 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
493 -
Workload Fluctuations
1
Related Content
- Want to learn more about SAP Master Data Governance at SAP Sapphire 2024? in Technology Blogs by SAP
- Tracking HANA Machine Learning experiments with MLflow: A conceptual guide for MLOps in Technology Blogs by SAP
- Tracking HANA Machine Learning experiments with MLflow: A technical Deep Dive in Technology Blogs by SAP
- Replication Flow Blog Part 6 – Confluent as Replication Target in Technology Blogs by SAP
- SAP Datasphere + SAP S/4HANA: Your Guide to Seamless Data Integration in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 20 | |
| 10 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |