
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Running SAP Cloud Application Programming Model wi...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-16-2019
9:11 PM
In my previous few blogs I've explored cloud based development environments and how they might be used in conjunction with SAP based development.
Throughout this series I've tried to demonstrate how SAP HANA and SAP Cloud Application Programming Model are not exclusive to the world of the SAP Web IDE nor SAP Cloud Platform. We left the last blog by showing how you could do your complete development in a cloud container but still connect to HANA As A Service and the User Authentication and Authorization of the SAP Cloud Platform. However the approach we used with the default-env.json is really only appropriate for local development and testing.
In this blog I'd like to take things a step further and show how you would package and deploy an SAP Cloud Application Programming Model application (with underlying HANA DB connection) to Kubernetes but replacing the default-env.json with the concept of a K8S Secret. By the end of this blog, we will have a single copy of application code that can run on XSA on premise, SAP Cloud Platform Cloud Foundry or any Kubernetes based environment with connectivity to a live HANA system.
There are many different options for running Kubernetes. I could have spun up a Kubernetes cluster on any of the major Cloud Hyperscalers.
As an SAP internal, I could have even used our internal Gardener environment to spin up Kubernetes to work on. So many options and honestly what I wanted to do would have worked pretty much the same on any of these environments.
But ultimately I decided that I wanted to setup my own Kubernetes environment locally on my laptop. There is a simple solution for this called Minikube:
https://kubernetes.io/docs/tasks/tools/install-minikube/
This should allow me to work with core Kubernetes functionality without having to get into the specifics of any particular Hyperscaler. It also allows me to play offline with zero cloud hosting costs.
Although there is a Minkube installation option for both MacOS and Windows, I ultimately decided I wanted to install and work within Linux. I already have an openSUSE VM image on my laptop, so I'll just install and work there. I see a couple of advantages with this approach. I can use VM snapshots to easily rollback the entire environment if I screw up (which I ended up doing once during this process). Also by using Linux I stay closest to the environment I will find later if I want to move this to the cloud on one of the Hyperscalers.
The other thing I decided to do is install Project Kyma on top of Minikube.
https://kyma-project.io/
Kyma is an open source project which originated at SAP which collects and adds lots of additional useful functionality on top of vanilla Kubernetes. Now for the purpose of this blog I won't really be using much of this additional functionality. The main part I'll utilize is just the Web UI for administration, but everything I show you there could also be done from the Kubernetes command line (kubectl).
So in order to get both Minikube and Kyma running in my VM, I've followed the installation instructions here:
https://kyma-project.io/docs/root/kyma/#installation-install-kyma-locally
I've got all the prerequisites downloaded, including the kyma command line tool itself. It will be doing most of the installation work. The kmya provision minikube command sets up the basic Kubernetes environment. From there I just need the kyma install command to download and setup all the additional services and applications.

Of course you can follow the rest of the Kyma installation instructions - such as installing the self signed certificates and testing out the Web Admin UI. For the purposes of this blog I'm going to assume the setup went perfectly according to the directions in the Kyma website and we are ready to develop.
I'm going to begin with an existing SAP Cloud Application Programming Model application. This is the same application I used in the previous blog and its just a very small example with two database tables which get exposed as a Node.js OData V4 service. I want to do all my coding within my Linux VM which does already have VS Code installed. So I'll start by cloning my existing CAPM project from Github at the state where is was working for the previous blog. If you remember, it was running the OData service and connecting to HANA As A Service on Cloud Platform using the default-env.json for the connection configuration.
https://github.com/jungsap/my-hana-capm

Before I start trying to run the OData service with connectivity to HANA, I want to focus on just deploying an application to Kubernetes. For this, let's change the Node.js application to something much simpler. I want just a little web server that will return Hello World and I will test locally just by running Node (via NPM) from the terminal. I can open the local browser and connect via localhost. So I have a working Node.js service, but that's not all that impressive.

Now is probably a good time to explain one of the major differences between Cloud Foundry and Kubernetes. Cloud Foundry has a very opinionated approach to deploying applications and services. They have small set of buildpacks with pre-configured container environments. A developer can choose one of the buildpacks but is generally limited in the configuration of the environment for each. Its a: "tell me which environment you want (Node, Java, etc) and I'll figure out the best way to get there" kind of a approach.
Kubernetes takes the opposite position. They give the developer much more responsibility and access to the entire environment building process. Instead of a small set of pre-configured environments, Kubernetes expects a Docker container as the starting image of any deployment. This means that even for our very basic hello world node.js application, we are going to want to build a docker image.
This begins with a Dockerfile that basically scripts the creation of a container image.
In this script we start with an existing Docker container named node:8. This will initialize a mostly empty container but it will have the Node.js Version 8 runtime installed and configured. From there we can focus on the parts that are specific to our application. We want to begin by copying the package.json into the container. Then we can run NPM INSTALL to download any necessary node.js modules. Then we copy all the source files from our project into the container. Finally we specify the HTTP Port we want to expose outside the container (3000) and then issue the start command (we want Node.js to run our index.js).
From the command prompt we can run the docker build command which will run our Dockerfile script and create an image locally.

Now we can test this docker image locally as well before we push it to a Docker registry or try to run it in Kubernetes. For this we have the docker run command. It will start the container image on the local machine. In the run command itself, I can map a public HTTP port to the internal one. This is why when I test with localhost in the browser I'm pointing to 49160 which redirects within the container to port 3000.

So I've established that my Docker container works as I intended so I'm ready to publish it in an external Docker registry. With Minikube its possible to keep all your Docker images locally, but I decided to try and remain as realistic as possible to how this would be done in the Cloud and use the public docker hub registry.

So my docker image is now available publicly. I could easily publish in any of the Cloud environments as well:

Now that I have my Docker container published, I'm ready to try and deploy this image to Kubernetes. Much like Cloud Foundry, the root deployment configuration file format is YAML (yay, because everybody loves YAML - right?). And this file does much the same kinds of things as the manifest.yml or mta.yaml in the Cloud Foundry world. In this file we can specify the docker image we want as our source, http ports, memory limits, environment values, etc. The really key value here is the container image specification. This tells Kubernetes where to go to get our Docker image as the heart of the content that will run.

We would then use the Kubernetes command line tool (kubectl) to create the services defined in this deployment.yaml file within the namespace capm.

This created a service, deployment, and one or more pods. We can check all of these objects at the kubectl command line or here is where the Kyma Admin UI is so handy - it can allow us to quickly view all the running objects that were just created.

I also created an exposed API and mapped a virtual hostname to this API endpoint (this is very similar to how Cloud Foundry uses hostname based routing). So I can test this now running on Kubernetes for real (with all the internal port re-routing just like Cloud Foundry).

We have a running Node.js service on Kubernetes and if that was all we were after it would be the end of a good day. But remember we want a more realistic application that connects to a HANA DB on Cloud Foundry - and we want to do this in a secure way without just hard coding passwords in code.
When you create an HDI container instance in Cloud Foundry/XSA; it creates the HANA Schema, users, passwords within the DB for you. Furthermore when you bind this service broker instance to your application all this security information is made available automatically for you. It might seem almost magical how easily this works and is often the reason why people incorrectly think these services can only be used in Cloud Foundry or XSA. In fact all that is really happening is that the binding inserts the security information (users, passwords, certificates) in to the environment variables of the application. We saw earlier that we can simulate these environment variables with a local file named default-env.json. But now lets see how we can do the same thing the Cloud Foundry binding does but using functionality from Kubernetes.
Kubernetes has a concept called Secrets.
https://kubernetes.io/docs/concepts/configuration/secret/
This is the primary way that Kubernetes provides to store sensitive information and make it available to running services and applications. Therefore its exactly designed for the kind of thing we want to do here. Now a secret can be created a few different ways. We can define it in our deployment.yaml or manually create it from the command line with kubectl. Either way it expects the deployment definition to have the sensitive information in Base64 encoding. But keep in mind that Base64 is NOT encryption. Its very easy to decode such information. Therefore be careful to place such information in source files that will not be committed to git. Instead consider storing them separately in a sensitive deployment information vault.
For our purposes we want to create the secret from the command line. It expects name/value pairs for the data to be stored in the secret. We actually already have our technical information in the default-env.json from earlier testing. Therefore I'll just use the jq tool in order to parse and pass the JSON information from the file into the create secret command.

We can also use the kubectl or Kyma Admin UI to view the secret and its Base64 encoded information:

This is the same thing as going to Cloud Foundry on the SAP Cloud Platform and looking at the sensitive data of a binding:

The truly beautify part of this is that Secrets in Kubernetes can be mapped to environment variables of the deployed service via the deployment yaml. Therefore we can map the secret values right to the exact same environment variable names used in Cloud Foundry. All of our code (even SAP delivered modules) will find this variable and not even realize they aren't running in Cloud Foundry and work perfectly fine!

In order to prove this is working, let's change the Node.js service to output the entire Environment, so we can see our secret values getting injected.

If we run the Node.js service locally; we get a lot of environment values, but notice there are no VCAP_SERVICES or TARGET_CONTAINER.

If we rebuild the Docker image and run the container locally, we see the same thing - no VCAP_SERVICES or TARGET_CONTAINER.

This is exactly what we would expect. We shouldn't see these variables because they only get injected within Kubernetes by the connection to the Secret.
So we are ready to test in Kubernetes to finally (I hope) see the variables from the Secret. We want to redploy the Docker image, so make sure the imagePullPolicy in the deployment.yaml is set to Always so that the image gets updated. Also we can't use the kubectl create command because the service and deployment already exist. Instead we use kubectl replace --force to update the existing service and deployment.

And finally we will see the two variables with the values being injected from the Secret.

We have the basics down and we can get the technical connection details securely injected into our application via the Secret. I think we are ready to go back to our "real" Node.js coding which runs the CAPM OData V4 service and some custom Node.js REST services (all of which will retrieve data from our HANA DB instance running on SAP Cloud Platform).
I'm going to have to make a few additions to my Docker configuration to make this more complex scenario work. In my earlier example I wasn't using any SAP Node.js modules, but now I need several. But Node.js within the standard Docker image doesn't know anything about the SAP namespace nor our NPM registry. So we need to add a .npmrc configuration file to adds the SAP registry. We also need to copy this configuration into our container in the Dockerfile configuration.

The other change I need to make to my Docker configuration has to do with the fact that in Cloud Application Programming Model we have our db definitions in CDS files in the db folder. I originally created my Dockerfile in the srv folder because I was only testing the simple example. Now I need the cds files from that other folder for my OData service to work. Therefore I move the Dockerfile up to the project root and add a copy for the db folder into the Docker image as well. I also change from index.js (with my simple test) to the server.js (with the full OData and REST service functionality).
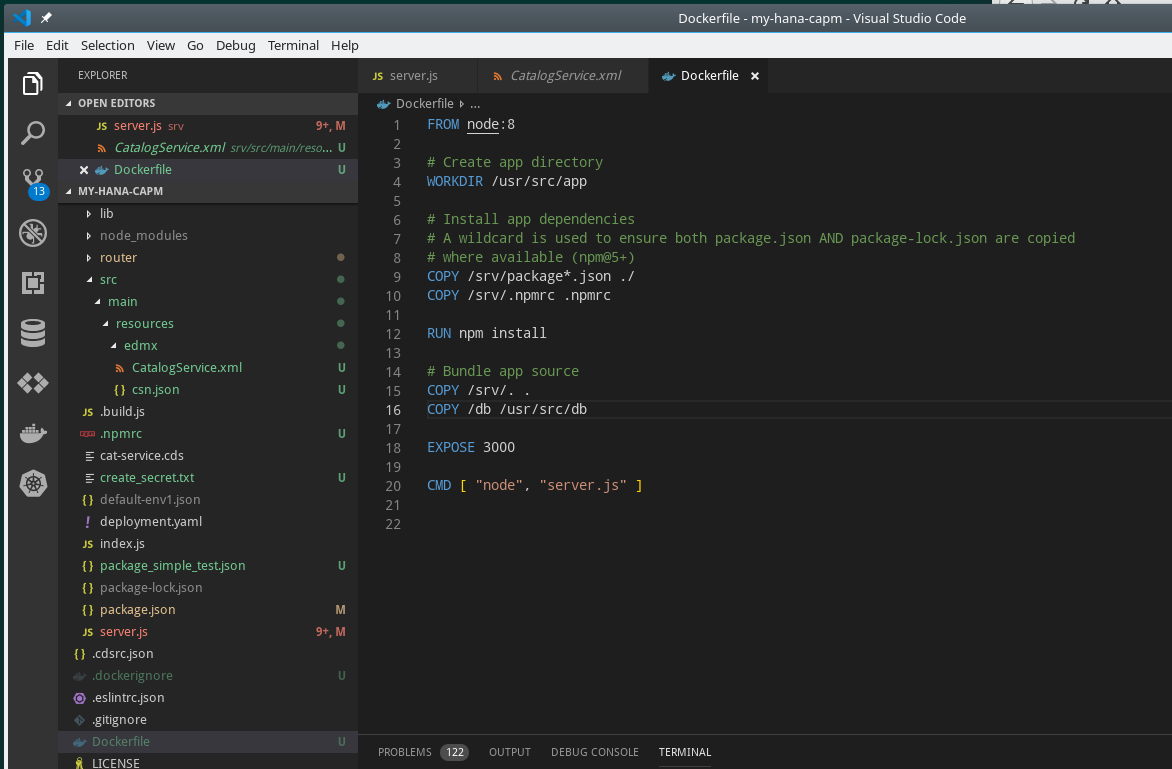
With those two small changes to the Docker setup, I'm ready to rebuild the Docker image, push it to the registry and then update the Kubernetes deployment. The moment of truth is here. I'm ready to test the CDS OData Service -
Well the Metadata request works fine:

And sure enough, I'm able to retrieve data from the HANA back end as well. This means all the Secret/env setup works perfectly to trick the standard @Sap/cds module. I didn't have to change a single line of application coding to make this work!

And just to be complete, let's also test a custom REST service that uses the @Sap/hdbext module to run a query in HANA that shows us the current DB user and Schema. It also works exactly as it does in Cloud Foundry:

Hopefully this blog helps dispel a lot of myths that I hear. Myths like HANA As A Service only works with Cloud Foundry or Cloud Application Programming Model can only deploy to Cloud Foundry. As this blog slows both of those are false. HANA As A Service is absolutely usable from other environments - in particular Kubernetes. And Cloud Application Programming Model applications totally can be deployed and run from Kubernetes - all without a single change to a line of application coding.
- https://blogs.sap.com/2019/07/11/sap-hana-development-from-alternative-ides/
- https://blogs.sap.com/2019/07/09/sap-development-using-amazon-cloud9/
- https://blogs.sap.com/2019/05/22/sap-development-using-google-cloud-shell/
- https://blogs.sap.com/2019/04/16/developing-with-hana-deployment-infrastructure-hdi-without-xsacf-or...
Throughout this series I've tried to demonstrate how SAP HANA and SAP Cloud Application Programming Model are not exclusive to the world of the SAP Web IDE nor SAP Cloud Platform. We left the last blog by showing how you could do your complete development in a cloud container but still connect to HANA As A Service and the User Authentication and Authorization of the SAP Cloud Platform. However the approach we used with the default-env.json is really only appropriate for local development and testing.
In this blog I'd like to take things a step further and show how you would package and deploy an SAP Cloud Application Programming Model application (with underlying HANA DB connection) to Kubernetes but replacing the default-env.json with the concept of a K8S Secret. By the end of this blog, we will have a single copy of application code that can run on XSA on premise, SAP Cloud Platform Cloud Foundry or any Kubernetes based environment with connectivity to a live HANA system.
Kubernetes Environment
There are many different options for running Kubernetes. I could have spun up a Kubernetes cluster on any of the major Cloud Hyperscalers.
As an SAP internal, I could have even used our internal Gardener environment to spin up Kubernetes to work on. So many options and honestly what I wanted to do would have worked pretty much the same on any of these environments.
But ultimately I decided that I wanted to setup my own Kubernetes environment locally on my laptop. There is a simple solution for this called Minikube:
https://kubernetes.io/docs/tasks/tools/install-minikube/
This should allow me to work with core Kubernetes functionality without having to get into the specifics of any particular Hyperscaler. It also allows me to play offline with zero cloud hosting costs.
Although there is a Minkube installation option for both MacOS and Windows, I ultimately decided I wanted to install and work within Linux. I already have an openSUSE VM image on my laptop, so I'll just install and work there. I see a couple of advantages with this approach. I can use VM snapshots to easily rollback the entire environment if I screw up (which I ended up doing once during this process). Also by using Linux I stay closest to the environment I will find later if I want to move this to the cloud on one of the Hyperscalers.
The other thing I decided to do is install Project Kyma on top of Minikube.
https://kyma-project.io/
Kyma is an open source project which originated at SAP which collects and adds lots of additional useful functionality on top of vanilla Kubernetes. Now for the purpose of this blog I won't really be using much of this additional functionality. The main part I'll utilize is just the Web UI for administration, but everything I show you there could also be done from the Kubernetes command line (kubectl).
So in order to get both Minikube and Kyma running in my VM, I've followed the installation instructions here:
https://kyma-project.io/docs/root/kyma/#installation-install-kyma-locally
I've got all the prerequisites downloaded, including the kyma command line tool itself. It will be doing most of the installation work. The kmya provision minikube command sets up the basic Kubernetes environment. From there I just need the kyma install command to download and setup all the additional services and applications.
Of course you can follow the rest of the Kyma installation instructions - such as installing the self signed certificates and testing out the Web Admin UI. For the purposes of this blog I'm going to assume the setup went perfectly according to the directions in the Kyma website and we are ready to develop.
Preparing Development for Docker
I'm going to begin with an existing SAP Cloud Application Programming Model application. This is the same application I used in the previous blog and its just a very small example with two database tables which get exposed as a Node.js OData V4 service. I want to do all my coding within my Linux VM which does already have VS Code installed. So I'll start by cloning my existing CAPM project from Github at the state where is was working for the previous blog. If you remember, it was running the OData service and connecting to HANA As A Service on Cloud Platform using the default-env.json for the connection configuration.
https://github.com/jungsap/my-hana-capm
Before I start trying to run the OData service with connectivity to HANA, I want to focus on just deploying an application to Kubernetes. For this, let's change the Node.js application to something much simpler. I want just a little web server that will return Hello World and I will test locally just by running Node (via NPM) from the terminal. I can open the local browser and connect via localhost. So I have a working Node.js service, but that's not all that impressive.
Now is probably a good time to explain one of the major differences between Cloud Foundry and Kubernetes. Cloud Foundry has a very opinionated approach to deploying applications and services. They have small set of buildpacks with pre-configured container environments. A developer can choose one of the buildpacks but is generally limited in the configuration of the environment for each. Its a: "tell me which environment you want (Node, Java, etc) and I'll figure out the best way to get there" kind of a approach.
Kubernetes takes the opposite position. They give the developer much more responsibility and access to the entire environment building process. Instead of a small set of pre-configured environments, Kubernetes expects a Docker container as the starting image of any deployment. This means that even for our very basic hello world node.js application, we are going to want to build a docker image.
This begins with a Dockerfile that basically scripts the creation of a container image.
FROM node:8
# Create app directory
WORKDIR /usr/src/app
# Install app dependencies
# A wildcard is used to ensure both package.json AND package-lock.json are copied
# where available (npm@5+)
COPY /srv/package*.json ./
RUN npm install
# Bundle app source
COPY . .
EXPOSE 3000
CMD [ "node", "index.js" ]In this script we start with an existing Docker container named node:8. This will initialize a mostly empty container but it will have the Node.js Version 8 runtime installed and configured. From there we can focus on the parts that are specific to our application. We want to begin by copying the package.json into the container. Then we can run NPM INSTALL to download any necessary node.js modules. Then we copy all the source files from our project into the container. Finally we specify the HTTP Port we want to expose outside the container (3000) and then issue the start command (we want Node.js to run our index.js).
From the command prompt we can run the docker build command which will run our Dockerfile script and create an image locally.
Now we can test this docker image locally as well before we push it to a Docker registry or try to run it in Kubernetes. For this we have the docker run command. It will start the container image on the local machine. In the run command itself, I can map a public HTTP port to the internal one. This is why when I test with localhost in the browser I'm pointing to 49160 which redirects within the container to port 3000.
So I've established that my Docker container works as I intended so I'm ready to publish it in an external Docker registry. With Minikube its possible to keep all your Docker images locally, but I decided to try and remain as realistic as possible to how this would be done in the Cloud and use the public docker hub registry.
So my docker image is now available publicly. I could easily publish in any of the Cloud environments as well:
Deploying to Kubernetes
Now that I have my Docker container published, I'm ready to try and deploy this image to Kubernetes. Much like Cloud Foundry, the root deployment configuration file format is YAML (yay, because everybody loves YAML - right?). And this file does much the same kinds of things as the manifest.yml or mta.yaml in the Cloud Foundry world. In this file we can specify the docker image we want as our source, http ports, memory limits, environment values, etc. The really key value here is the container image specification. This tells Kubernetes where to go to get our Docker image as the heart of the content that will run.
We would then use the Kubernetes command line tool (kubectl) to create the services defined in this deployment.yaml file within the namespace capm.
This created a service, deployment, and one or more pods. We can check all of these objects at the kubectl command line or here is where the Kyma Admin UI is so handy - it can allow us to quickly view all the running objects that were just created.
I also created an exposed API and mapped a virtual hostname to this API endpoint (this is very similar to how Cloud Foundry uses hostname based routing). So I can test this now running on Kubernetes for real (with all the internal port re-routing just like Cloud Foundry).
Kubernetes Secrets
We have a running Node.js service on Kubernetes and if that was all we were after it would be the end of a good day. But remember we want a more realistic application that connects to a HANA DB on Cloud Foundry - and we want to do this in a secure way without just hard coding passwords in code.
When you create an HDI container instance in Cloud Foundry/XSA; it creates the HANA Schema, users, passwords within the DB for you. Furthermore when you bind this service broker instance to your application all this security information is made available automatically for you. It might seem almost magical how easily this works and is often the reason why people incorrectly think these services can only be used in Cloud Foundry or XSA. In fact all that is really happening is that the binding inserts the security information (users, passwords, certificates) in to the environment variables of the application. We saw earlier that we can simulate these environment variables with a local file named default-env.json. But now lets see how we can do the same thing the Cloud Foundry binding does but using functionality from Kubernetes.
Kubernetes has a concept called Secrets.
https://kubernetes.io/docs/concepts/configuration/secret/
This is the primary way that Kubernetes provides to store sensitive information and make it available to running services and applications. Therefore its exactly designed for the kind of thing we want to do here. Now a secret can be created a few different ways. We can define it in our deployment.yaml or manually create it from the command line with kubectl. Either way it expects the deployment definition to have the sensitive information in Base64 encoding. But keep in mind that Base64 is NOT encryption. Its very easy to decode such information. Therefore be careful to place such information in source files that will not be committed to git. Instead consider storing them separately in a sensitive deployment information vault.
For our purposes we want to create the secret from the command line. It expects name/value pairs for the data to be stored in the secret. We actually already have our technical information in the default-env.json from earlier testing. Therefore I'll just use the jq tool in order to parse and pass the JSON information from the file into the create secret command.
We can also use the kubectl or Kyma Admin UI to view the secret and its Base64 encoded information:
This is the same thing as going to Cloud Foundry on the SAP Cloud Platform and looking at the sensitive data of a binding:
The truly beautify part of this is that Secrets in Kubernetes can be mapped to environment variables of the deployed service via the deployment yaml. Therefore we can map the secret values right to the exact same environment variable names used in Cloud Foundry. All of our code (even SAP delivered modules) will find this variable and not even realize they aren't running in Cloud Foundry and work perfectly fine!
In order to prove this is working, let's change the Node.js service to output the entire Environment, so we can see our secret values getting injected.
If we run the Node.js service locally; we get a lot of environment values, but notice there are no VCAP_SERVICES or TARGET_CONTAINER.
If we rebuild the Docker image and run the container locally, we see the same thing - no VCAP_SERVICES or TARGET_CONTAINER.
This is exactly what we would expect. We shouldn't see these variables because they only get injected within Kubernetes by the connection to the Secret.
So we are ready to test in Kubernetes to finally (I hope) see the variables from the Secret. We want to redploy the Docker image, so make sure the imagePullPolicy in the deployment.yaml is set to Always so that the image gets updated. Also we can't use the kubectl create command because the service and deployment already exist. Instead we use kubectl replace --force to update the existing service and deployment.
And finally we will see the two variables with the values being injected from the Secret.
Putting It All Together
We have the basics down and we can get the technical connection details securely injected into our application via the Secret. I think we are ready to go back to our "real" Node.js coding which runs the CAPM OData V4 service and some custom Node.js REST services (all of which will retrieve data from our HANA DB instance running on SAP Cloud Platform).
I'm going to have to make a few additions to my Docker configuration to make this more complex scenario work. In my earlier example I wasn't using any SAP Node.js modules, but now I need several. But Node.js within the standard Docker image doesn't know anything about the SAP namespace nor our NPM registry. So we need to add a .npmrc configuration file to adds the SAP registry. We also need to copy this configuration into our container in the Dockerfile configuration.
The other change I need to make to my Docker configuration has to do with the fact that in Cloud Application Programming Model we have our db definitions in CDS files in the db folder. I originally created my Dockerfile in the srv folder because I was only testing the simple example. Now I need the cds files from that other folder for my OData service to work. Therefore I move the Dockerfile up to the project root and add a copy for the db folder into the Docker image as well. I also change from index.js (with my simple test) to the server.js (with the full OData and REST service functionality).
With those two small changes to the Docker setup, I'm ready to rebuild the Docker image, push it to the registry and then update the Kubernetes deployment. The moment of truth is here. I'm ready to test the CDS OData Service -
Well the Metadata request works fine:
And sure enough, I'm able to retrieve data from the HANA back end as well. This means all the Secret/env setup works perfectly to trick the standard @Sap/cds module. I didn't have to change a single line of application coding to make this work!
And just to be complete, let's also test a custom REST service that uses the @Sap/hdbext module to run a query in HANA that shows us the current DB user and Schema. It also works exactly as it does in Cloud Foundry:
Hopefully this blog helps dispel a lot of myths that I hear. Myths like HANA As A Service only works with Cloud Foundry or Cloud Application Programming Model can only deploy to Cloud Foundry. As this blog slows both of those are false. HANA As A Service is absolutely usable from other environments - in particular Kubernetes. And Cloud Application Programming Model applications totally can be deployed and run from Kubernetes - all without a single change to a line of application coding.
Labels:
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- Improving Time Management in SAP S/4HANA Cloud: A GenAI Solution in Technology Blogs by SAP
- Embracing TypeScript in SAPUI5 Development in Technology Blogs by Members
- Mistral gagnant. Mistral AI and SAP Kyma serverless. in Technology Blogs by SAP
- Configure Custom SAP IAS tenant with SAP BTP Kyma runtime environment in Technology Blogs by SAP
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 14 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |